
Processing Pipeline
The .readDoc() method, when used with the default instance of winkNLP, splits the text into tokens, entities, and sentences. It also determines a range of their properties. These are accessible via the .out() method on the basis of the input parameter — its.property. Some examples of properties are value, stopWordFlag, pos, and lemma:
const text = 'cats are cool';
const doc = nlp.readDoc( text );
console.log( doc.tokens().out( its.value) );
// -> ["cats", "are", "cool"]
console.log( doc.tokens().out( its.stopWordFlag ) );
// -> [false, true, false]
console.log( doc.tokens().out( its.pos ) );
// -> ["NOUN", "AUX", "VERB"]
console.log( doc.tokens().out( its.lemma ) );
// -> ["cat", "be", "cool"].readDoc() API processes the input text in many stages. All the stages together form a processing pipeline also referred as pipe. The first stage is tokenization, which is mandatory. The later stages such as sentence boundary detection (SBD) or part-of-speech tagging (POS) are optional. The optional stages are user configurable. The following figure and table illustrates the pipe:
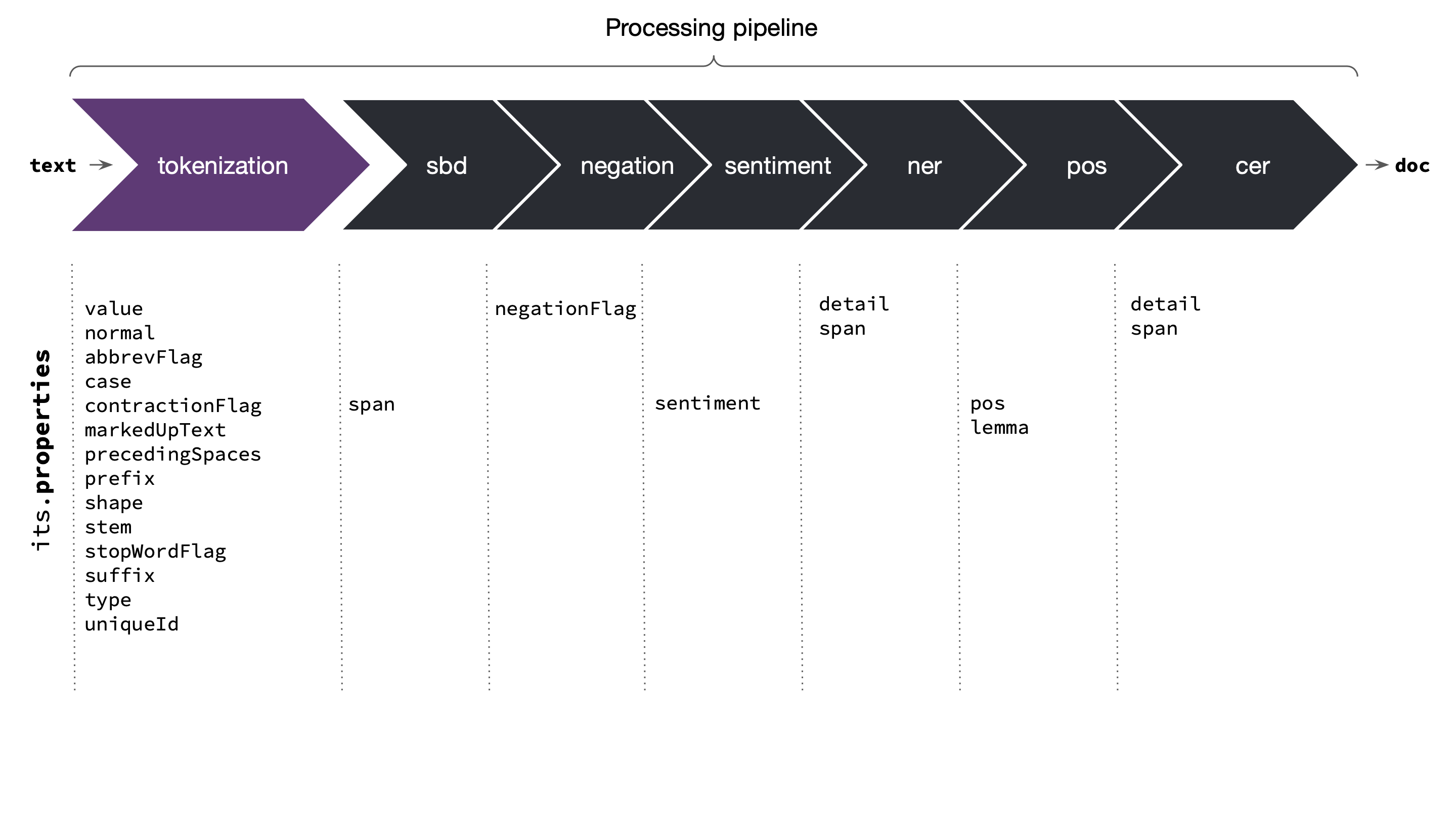
Common its.properties that become available at each stage are also highlighted. For more details please refer to sections on item and its properties and its & as helpers.
| Stage | Description |
|---|---|
tokenization | Splits text into tokens. |
sbd | Sentence boundary detection — determines **span** of each sentence in terms of start & end token indexes. |
negation | Negation handling — sets the negationFlag for every token whose meaning is negated due a "not" word. |
sentiment | Computes sentiment score of each sentence and the entire document. |
ner | Named entity recognition — detects all named entities and also determines their type & span. |
pos | Performs part-of-speech (pos) tagging. |
cer | Custom entity recognition — detects all custom entities and their type & span. The detection is carried out on the basis of training carried out using learnCustomEntities() method. |
The default instance of winkNLP is created using only the model as input parameter:
// Load wink-nlp package.
const winkNLP = require( 'wink-nlp' );
// Load english language model.
const model = require( 'wink-eng-lite-web-model' );
// Instantiate winkNLP — default — will run all the above mentioned
// stages.
const nlp = winkNLP( model );It also accepts an additional parameter — pipe that controls the processing pipeline. This parameter is an array that contains the names of the stages that you wish to run. For example, the following will only run sentence boundary detection and pos tagging after tokenization:
const nlp = winkNLP( model, [ 'sbd', 'pos' ] );- While the sequence of stages in a pipe is not important as `winkNLP` handles it automatically, it is recommended to always provide names in the correct logical sequence.
- Without `sbd`, the entire text is treated as a single sentence.
- `sentiment` is dependent on `negation`; without negation, the accuracy of sentiment score may drop.
- Without `pos`, `its.lemma` accuracy drops drastically.
- Without `ner`, the count of named entities will always be zero i.e. `doc.entities().length()` will return a zero.
- Without `cer`, the count of custom entities will always be zero i.e. `doc.customEntities().length()` will return a zero.